论文思路
1
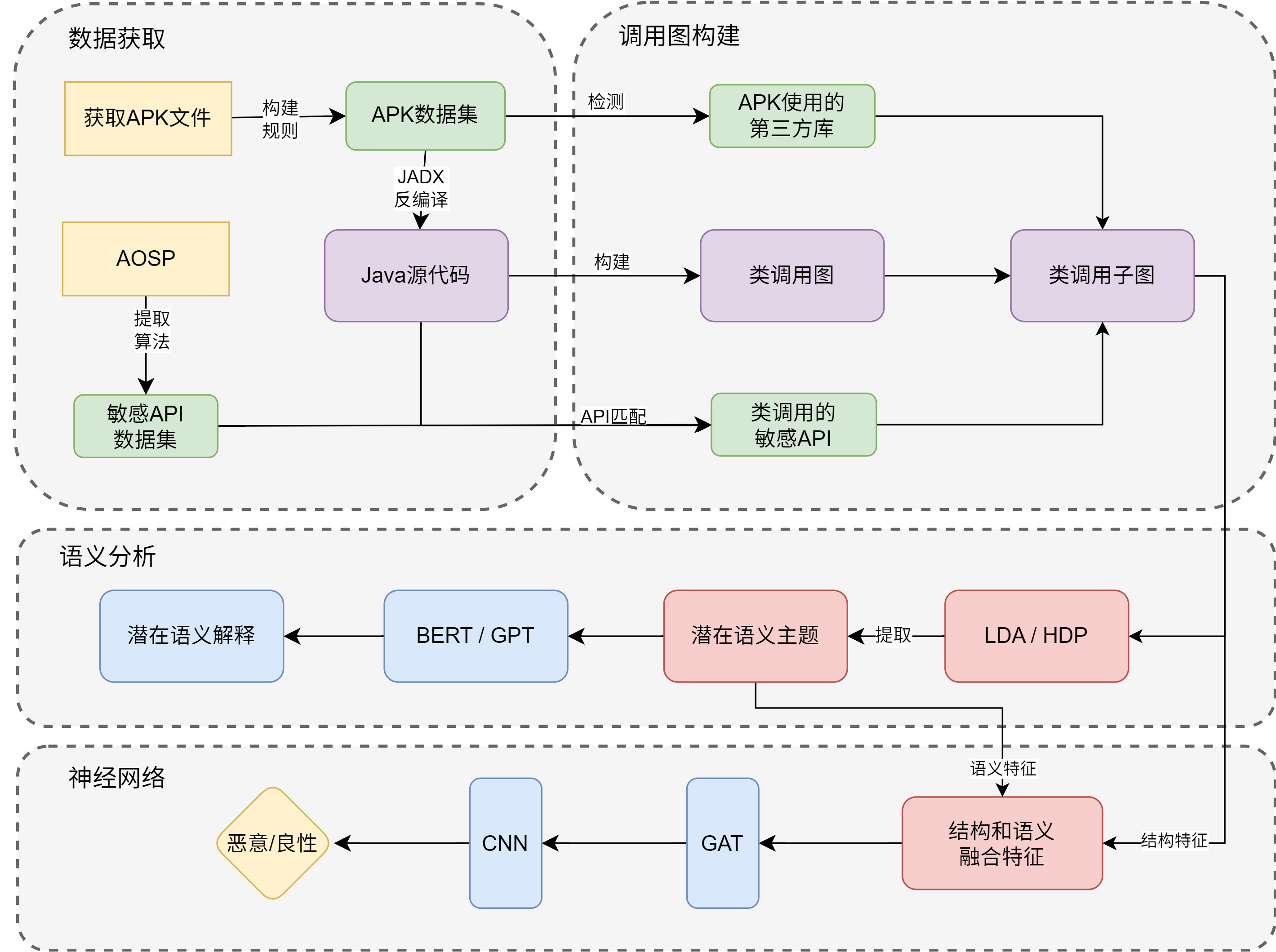
2
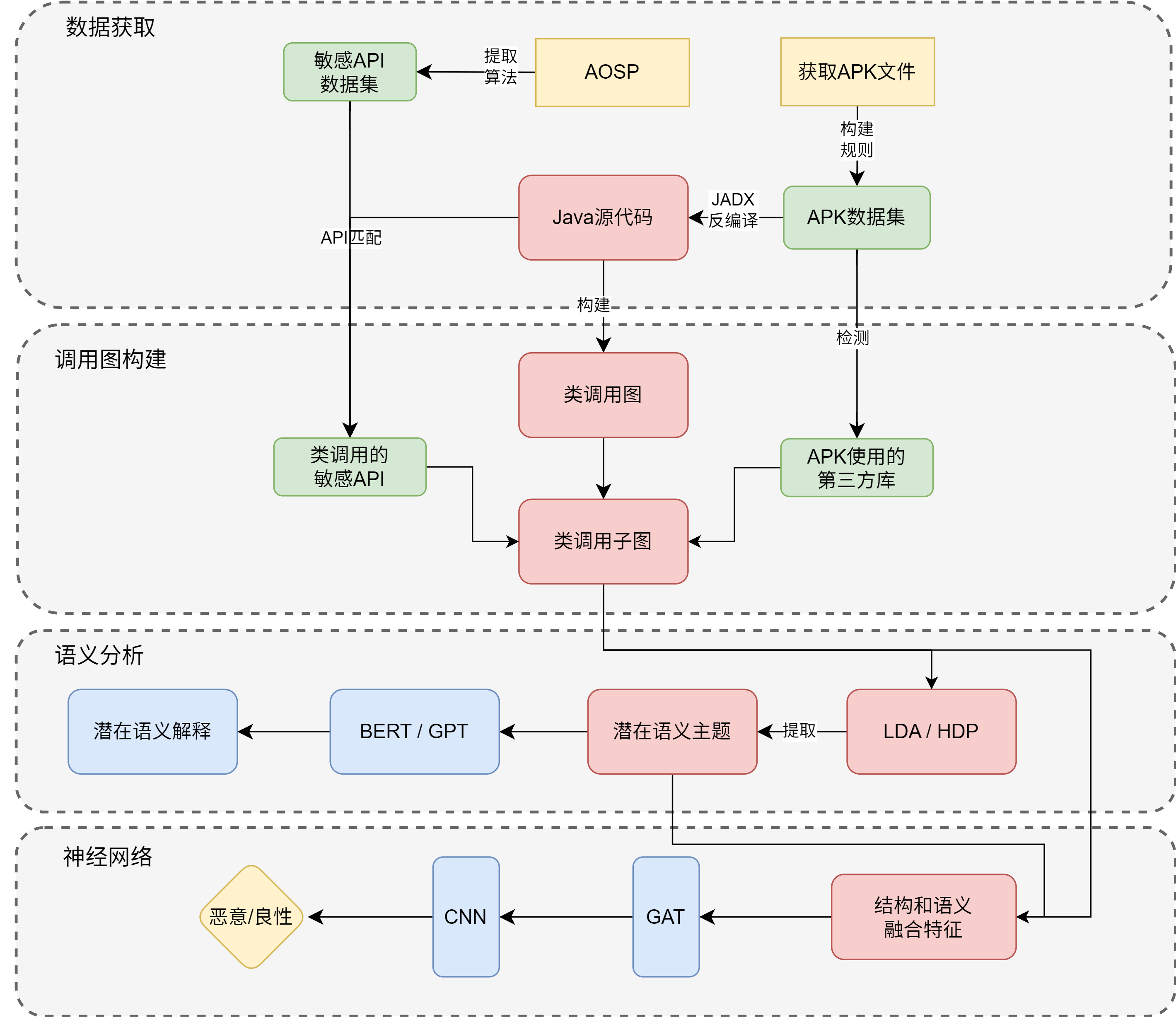
3
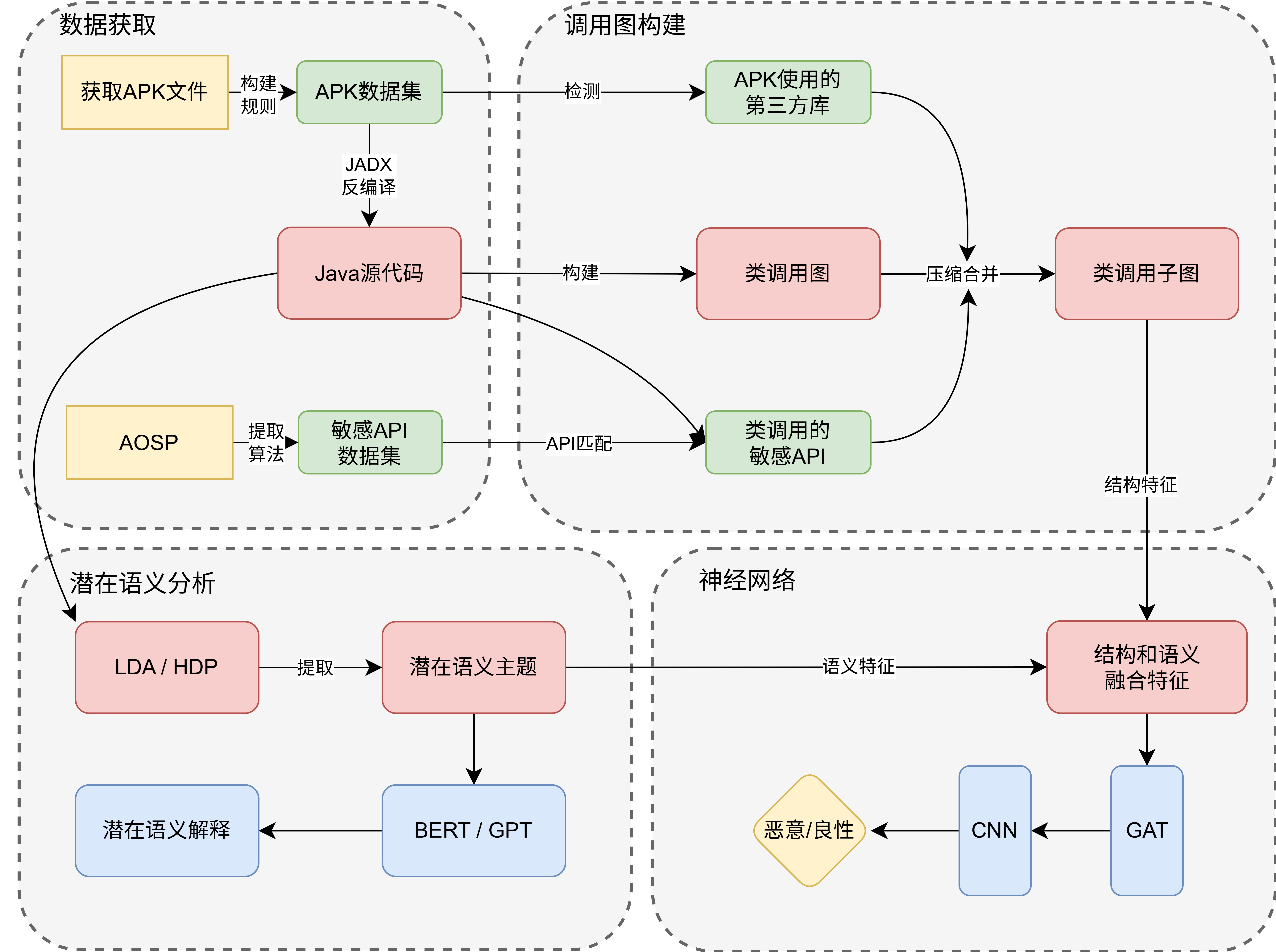
关于GAT_AMD的主题模型方法的创新点思路
这篇文章的方法现在总结一下:
- 先总结作者上一篇文章
- 使用主题模型来提取代码文本的主题,并把主题作为特征使用机器学习模型进行训练和检测。
- 反编译java代码、59维权限特征
- 主题模型对java代码提取主题
- 使用LSI和XGboost两个模型
- 使用主题模型来提取代码文本的主题,并把主题作为特征使用机器学习模型进行训练和检测。
- 下一篇文章是在上一篇文章的主题模型前添加了CSCG和GAT
某思路
- 这里的59维权限特征我可以用之前搞过的android源代码提取权限构建自己的敏感权限数据集,和apk提取的数据集进行匹配(取交集),这可以取个高大上的名字作为权限提取的创新点
- 这里看到一篇文献和我复现的提取api权限信息相近的文献2022.03.SDAC:使用基于语义距离的 API 集群进行 Android 恶意软件检测的慢老化解决方案
- 用在第三方库检测,现在的检测手段过失,很多新的库无法检测
- 我提出一个新的检测方法,从安卓源代码中提取第三方库建立数据库
- 随着安卓版本的提升,只需要根据源代码重新建议一遍数据库
- 添加transformer和注意力机制到语义特征提取里面
- 关于LSI的改进方法(LSI也能叫LSA)
- 参考这篇文章文本主题模型之潜在语义索引(LSI) - 刘建平Pinard - 博客园
1) SVD计算非常的耗时,尤其是我们的文本处理,词和文本数都是非常大的,对于这样的高维度矩阵做奇异值分解非常难。- 主题模型非负矩阵分解(NMF)可以解决矩阵分解的速度问题。
2) 主题值的选取对结果的影响非常大,很难选择合适的k值。 - 老大难问题,大部分主题模型的主题的个数选取一般都是凭经验的,较新的层次狄利克雷过程(HDP)可以自动选择主题个数。
3) LSI得到的不是一个概率模型,缺乏统计基础,结果难以直观的解释。 - 牛人们整出了pLSI(也叫pLSA)和隐含狄利克雷分布(LDA)这类基于概率分布的主题模型来替代基于矩阵分解的主题模型。
回到LSI本身,对于一些规模较小的问题,如果想快速粗粒度的找出一些主题分布的关系,则LSI是比较好的一个选择,其他时候,如果需要使用主题模型,使用LDA和HDP更合适。
- 主题模型非负矩阵分解(NMF)可以解决矩阵分解的速度问题。
- 参考这篇文章文本主题模型之潜在语义索引(LSI) - 刘建平Pinard - 博客园
- 讲故事:
- 当今GPU资源紧张状态,一味堆深度学习只会在大幅增加算力资源消耗的情况下获得相对较低的性能提升,我们的方法在gpu算力上的要求很低
Note
王,两想法,
- 一个是从安卓源代码里提取权限敏感度特征数据集,从apk数据集中提取权限,然后做敏感度特征匹配,作为一个新特征
- 还有现在transformer很火,我最近看的几篇文章都是语义分析相关的,我在想能不能把transformer结合到恶意代码的语义分析中去c
王振东:有想法就去实现,看看效果如何
关于做实验
准确率等参数对比实验
消融实验
恶意软件进化实验
训练时间复杂度实验
apk部署模型实验