352-线程
多任务的实现方法有:
- 多进程
- 多线程
- 协程
掌握:
- 线程的介绍
- 多线程完成多任务
- 线程执行带有参数的任务
- 主线程和子线程的结束顺序
- 线程间的执行顺序
- 线程间共享全局变量
- 进程和线程对比
线程
线程的介绍
使用多任务的另一种方式
进程是分配资源的最小单位,一旦创建一个进程就会分配一定的资源,就像跟两个人聊QQ就需要打开两个QQ软件一样是比较浪费资源的.
线程是程序执行的最小单位,实际上进程只负责分配资源,而利用这些资源执行程序的是线程,也就说进程是线程的容器,一个进程中最少有一个线程来负责执行程序.同时线程自己不拥有系统资源,只需要一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源.这就像通过一个QQ软件(一个进程)打开两个窗口(两个线程)跟两个人聊天一样,实现多任务的同时也节省了资源
为什么使用多线程?
- 进程的创建和销毁开销大,效率低。
- 线程的创建和销毁开销小,效率高。
- 线程的执行效率高,切换速度快。
- 线程的执行效率高,切换速度快。
进程是分配资源的最小单位,
线程是执行任务的最小单位。
进程和线程是包含的关系:
- 一个进程中可以有多个线程。
- 一个线程必须在一个进程中执行。
什么时候使用线程?
- 偏CPU计算任务(多任务计算)(使用大量cpu资源),推荐多进程
- 偏IO型任务(网络连接、文件操作)(使用少量cpu资源),推荐多线程
- 多任务执行时,需要共享同一个全局变量。
- 多任务执行时,需要共享同一个文件。
- 多任务执行时,需要共享同一个网络连接。
- 多任务执行时,需要共享多个数据。
区别
多进程:在CPU允许的情况下是并行,否则是并发。
多线程:多任务,底层是并发,单个核心里执行
多线程的作用
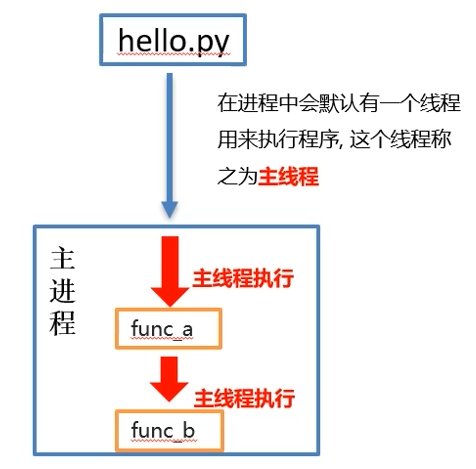
一个python程序,在执行的时候有一个主进程,进程默认有一个线程用来执行程序,这个线程成为主线程
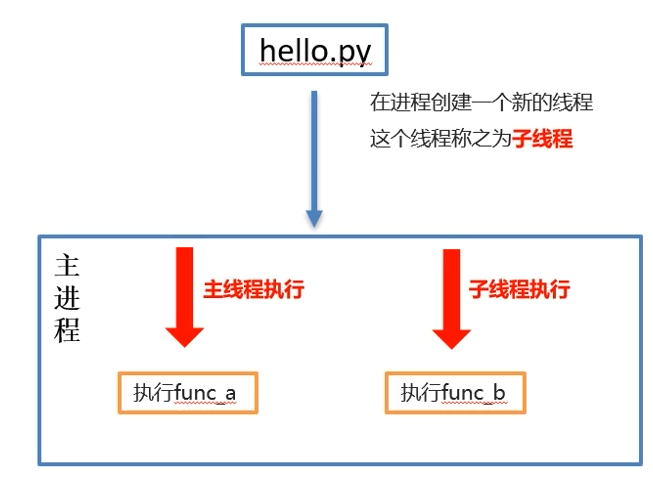
在进程创建一个新的线程,这个线程成为子线程
多线程编程
总结就是三步走:
- 导入threading模块:
import threading - 创建线程对象:
线程对象 = threading.Thread(target=函数名, args=(参数1, 参数2, ...)) - 启动线程执行任务:
线程对象.start()
通过线程类创建线程对象
线程对象 = threading.Thread(target=函数名, args=(参数1, 参数2, ...))
参数:
- target:执行的目标任务名,这里指的是函数名(方法名)
- name:线程名,一般不用设置
- group:线程组,目前只能使用None
- args:以元组的方式给执行任务传参==(‼️注意元组的单个参数的格式:args=("张三",))==
- kwargs:以字典的方式给执行任务传参(‼️注意字典格式:kwargs={"name": "张三"})
示例代码(单线程):
import time
def music():
for i in range(2):
print("正在听音乐")
time.sleep(1)
def game():
for i in range(2):
print("正在玩游戏")
time.sleep(1)
if __name__ == "__main__":
music()
game()
示例代码(多线程):
import time
# 第一步:导入多线程模块
import threading
def music():
for i in range(2):
print("正在听音乐")
time.sleep(1)
def game():
for i in range(2):
print("正在玩游戏")
time.sleep(1)
if __name__ == "__main__":
# 第二步:创建线程对象
music_thread = threading.Thread(target=music)
game_thread = threading.Thread(target=game)
# 第三步:启动线程执行任务
music_thread.start()
game_thread.start()
示例代码(多线程+传参):
import time
# 第一步:导入多线程模块
import threading
def music(name):
for i in range(2):
print(f"{name}正在听音乐")
time.sleep(1)
if __name__ == "__main__":
# 第二步:创建线程对象,这里传入参数(‼️注意元组格式)
music_thread = threading.Thread(target=music, args=("张三",))
# 第三步:启动线程执行任务
music_thread.start()
问题:多线程全局变量共享
多进程无法共享全局变量,
多线程可以共享全局变量,因为所有线程都共享同一个进程的资源。
import threading
import time
my_list = []
# 定义一个write_data()任务
def write_data():
for i in range(5):
my_list.append(i)
print(my_list)
print(my_list)
# 定义一个read_data()任务
def read_data():
print(my_list)
if __name__ == "__main__":
# 创建线程对象
write_thread = threading.Thread(target=write_data)
read_thread = threading.Thread(target=read_data)
# 启动线程执行任务
write_thread.start()
time.sleep(1)
read_thread.start()
问题:主线程和子线程的结束顺序
主线程会等待所有子线程执行完毕后才结束,所以主线程会阻塞等待子线程执行完毕。
示例代码:
import threading
import time
def task():
for i in range(5):
print(f"子线程{i}")
time.sleep(1)
if __name__ == "__main__":
# 创建线程对象
thread = threading.Thread(target=task)
# 启动线程执行任务
thread.start()
print("主线程结束(不等待子进程结束版本)") # 这句话会提前打印,但是代码不会结束,因为主线程会等待子线程执行完毕后才结束
# 如果想要等待子线程执行完毕后再执行print,可以使用join()方法
thread.join()
print("主线程结束(等待子进程结束版本)")
守护线程
守护线程:当主线程结束时,子线程也被结束
为什么叫守护主线程?
方案1:
sub_thread = threading.Thread(target=task, daemon=True)
方案2:
sub_thread = threading.Thread(target=task)
sub_thread.setDaemon(True)
示例代码:
import threading
import time
def task():
for i in range(5):
print(f"子线程{i}")
time.sleep(1)
if __name__ == "__main__":
sub_thread = threading.Thread(target=task, daemon=True)
sub_thread.start()
time.sleep(2)
print("主线程结束")
问题:线程的执行顺序
线程之间的执行是无序的,谁先执行谁后执行,取决于CPU的调度算法。
单任务是一步一步执行
多任务是先将任务提交到cpu,再由cpu统一调度执行
![note] 新方法:获取进程的信息
通过current_thread()方法获取线程对象
current_thread = threading.current_thread()
通过`current_thread对象可以知道线程的相关信息,例如被创建的顺序
print(current_thread)
代码示例:
import threading
import time
def get_info():
time.sleep(0.2)
current_thread = threading.current_thread()
print(current_thread)
if __name__ == "__main__":
for i in range(5):
sub_thread = threading.Thread(target=get_info)
sub_thread.start()