4-MapReduce、YARN、HA
hadoop离线day04--Hadoop MapReduce、YARN、HA
今日课程学习目标
理解分布式计算分而治之的思想
学会提交MapReduce程序
掌握MapReduce执行流程
掌握YARN功能与架构组件
掌握程序提交YARN交互流程
理解YARN调度策略
掌握Hadoop HA实现原理
今日课程内容大纲
#1、初识MapReduce
MapReduce背后的思想 先分再合,分而治之
MapReduce设计构思
官方MapReduce示例
MapReduce Python接口
#2、MapReduce基本原理
整体流程梳理
map阶段执行流程
reduce阶段执行流程
shuffle机制
#3、Hadoop YARN
介绍:集群资源管理 任务调度
3大组件 架构
程序在yarn运行流程:以mr程序提交为例
yarn调度器
#4、Hadoop HA集群
高可用概念:持续可用 一直可用
解决单点故障问题 主备集群
Hadoop HDFS HA实现方案--QJM、YARN HA
搭建HA集群
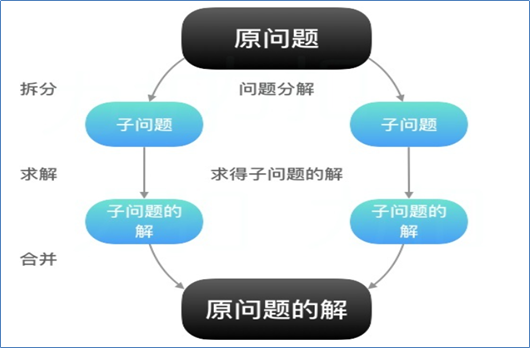
知识点01:Hadoop MapReduce--理解分而治之的思想
-
核心:先分再合,分而治之。:拆分,求解,合并
-
使用场景:面对复杂的任务、庞大的任务如何高效处理?
-
步骤
-
分的阶段(局部并行计算)--map
把复杂的任务拆分成若干个小的任务。 拆分的目的以并行方式处理小任务提高效率。 #前提:任务可以拆分,拆分之后没有依赖关系。 结果:每个任务处理完都是一个局部的结果。 map侧重于映射(对应关系) 任务1-->结果1 任务2-->结果2 -
汇总阶段(全局汇总计算)--reduce
把上一个分的阶段局部结果进行全局汇总 得到最终结果。 reduce指的是结果数量的减少 汇总。
-
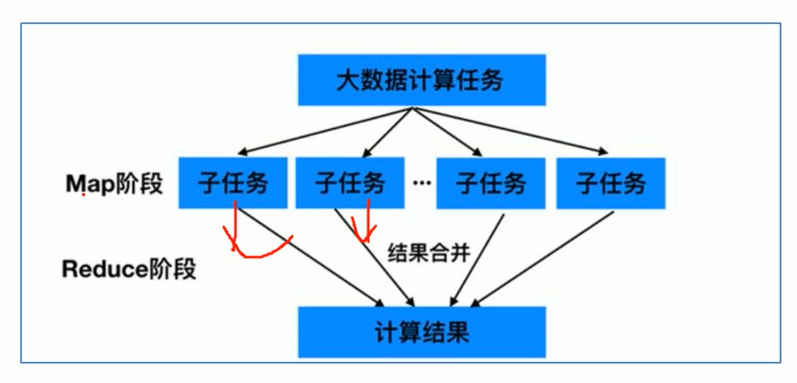
知识点02:Hadoop MapReduce--官方团队设计构思
!Pasted image 20250309210336.png
!Pasted image 20250309211508.png
-
如何面对大数据场景
#使用MapReduce思路来处理大数据。 先把数据集拆分若干个小的数据集,前提是可以拆分并且拆分之后没有依赖。 拆分之后可以并行计算提高计算。 再通过全局汇总计算得出最终结果。 -
构建了函数式编程模型Map Reduce
#函数本质就是映射。 f(x)=2x+1 当x=1 f(1)=3 当x=2 f(2)=5 x-->f(x) 一一对应的映射关系。 #对应MapReduce来说 每个阶段都是输入数据经过处理对应着输出。 MapReduce处理的数据类型是<key,value>键值对。 实际使用中 考虑每个阶段输入输出 key value是什么。 -
统一构架,隐藏系统层细节
精准的把技术问题和业务问题区分。 技术是通用的 业务不通用的。 hadoop实现了底层所有的技术问题。 --->90%代码 怎么做(how to do) 用户实现业务问题 --->10%代码 做什么(what need to do) 使用简单不代表技术简单 只能说MapReduce底层封装太漂亮。
知识点03:Hadoop MapReduce官方示例--计算圆周率(如何提交mr到yarn)
最终MR程序需要用户的代码和Hadoop自己实现的代码整合在一起 才能叫做完整MR程序。
由于当下企业中MapReduce计算引擎已经日薄西山,所以很少涉及到MapReduce编程了。
可以通过官方提供的示例来感受MapReduce。

-
提交程序
[root@node1 mapreduce]# pwd /export/server/hadoop-3.3.0/share/hadoop/mapreduce [root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 10 50 #第一个参数:pi表示MapReduce程序执行圆周率计算任务; #第二个参数:用于指定map阶段运行的任务task次数,并发度,这里是10; #第三个参数:用于指定每个map任务取样的个数,这里是50。 -
执行过程日志观察与梳理
#mr程序的执行需要硬件资源(cpu ram) 而yarn正好管理这些资源 所以第一步首先连接yarn申请资源 #mr程序分为两步 - map阶段 - reduce阶段 #每个阶段都会运行task任务 map阶段的任务叫做maptask reduce阶段的任务叫做reducetask.
知识点04:Hadoop MapReduce官方示例--单词统计(WordCount)需求剖析
-
背景
网页倒排索引 统计关键字在页面中出现的次数。 -
业务需求
统计文件中每个单词出现的总次数。
-
实现思路
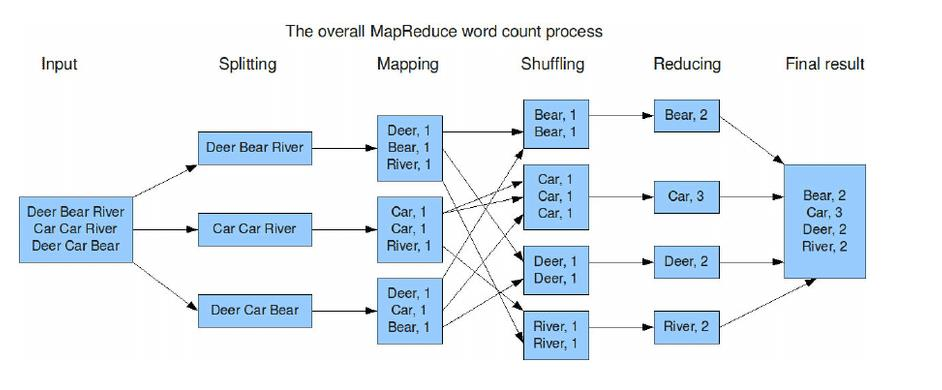
#map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是<单词,1>。
#shuffle阶段核心:经过默认的排序分区分组,key相同的单词会作为一组数据构成新的kv对。
#reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是单词的总次数。
#读取数据组件 写出数据组件MR框架已经封装好(自带)
-
程序提交
#上传课程资料中的文本文件1.txt到HDFS文件系统的/input目录下,如果没有这个目录,使用shell创建 hadoop fs -mkdir /input hadoop fs -put 1.txt /input #准备好之后,执行官方MapReduce实例,对上述文件进行单词次数统计 第一个参数:wordcount表示执行单词统计任务; 第二个参数:指定输入文件的路径; 第三个参数:指定输出结果的路径(该路径不能已存在) [root@node1 mapreduce]# pwd /export/server/hadoop-3.3.0/share/hadoop/mapreduce [root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
知识点05:Hadoop MapReduce官方示例--Wordcount--java代码梳理
-
mapper
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //每一次读取到一行内容 String line = value.toString(); //根据分隔符进行切割 String[] words = line.split("\\s+"); //遍历单词数组 for (String word : words) { //输出数据 把每个单词标记1 <单词,1> //使用框架提供的上下文对象 进行数据的输出 context.write(new Text(word),new IntWritable(1)); } } } -
reducer
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> { /** * Q: 当所有的数据来到reducer之后 内部有什么行为? * <hello,1><hadoop,1><hello,1><hello,1><hadoop,1> 1、所有的数据排序 排序规则:key的字典序 a-z * <hadoop,1><hadoop,1><hello,1><hello,1><hello,1> * 2、分组grouping 分组规则:key相同的分为一组 * <hadoop,1><hadoop,1> * <hello,1><hello,1><hello,1> 3、每组构成一个新的kv对 去调用reduce方法 * 新key: 该组共同的key * 新value: 该组所有的value组成的一个迭代器Iterable(理解为类似于集合数据结构) * <hadoop,1><hadoop,1> ----> <hadoop,Iterable[1,1]> * <hello,1><hello,1><hello,1> ---> <hello,Iterable[1,1,1]> */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //定义个统计变量 int count = 0; //遍历迭代器 for (IntWritable value : values) { //累加 count += value.get(); } //使用上下文输出结果 context.write(key,new IntWritable(count)); } }
知识点06:Hadoop MapReduce--python接口接入
#虽然Hadoop是用Java编写的一个框架, 但是并不意味着他只能使用Java语言来操作;
#在Hadoop-0.14.1版本后, Hadoop支持了Python和C++语言;
#在Python中的sys包中存在stdin和stdout(输入输出流), 可以利用这个方式来进行MapReduce的编写;
#在Hadoop的文档中提到了Hadoop Streaming, 可以使用流的方式来操作它;
https://hadoop.apache.org/docs/r3.3.0/hadoop-streaming/HadoopStreaming.html
-
import sys for line in sys.stdin: # 捕获输入流 line = line.strip() # 根据分隔符切割单词 words = line.split() # 遍历单词列表 每个标记1 for word in words: print("%s\t%s" % (word, 1)) -
import sys # 保存单词次数的字典 key:单词 value:总次数 word_dict = {} for line in sys.stdin: line = line.strip() word, count = line.split('\t') # count类型转换 try: count = int(count) except ValueError: continue # 如果单词位于字典中 +1,如果不存在 保存并设初始值1 if word in word_dict: word_dict[word] += 1 else: word_dict.setdefault(word, 1) # 结果遍历输出 for k, v in word_dict.items(): print('%s\t%s' % (k, v))
知识点07:Hadoop MapReduce--Hadoop Streaing提交python脚本
-
Python3在Linux安装
#1、安装编译相关工具 yum -y groupinstall "Development tools" yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel yum install libffi-devel -y #2、解压Python安装包 tar -zxvf Python-3.8.5.tgz #3、编译、安装Python mkdir /usr/local/python3 #创建编译安装目录 cd Python-3.8.5 ./configure --prefix=/usr/local/python3 make && make install #make编译c源码 make install 编译后的安装 #安装过,出现下面两行就成功了 Installing collected packages: setuptools, pip Successfully installed pip-20.1.1 setuptools-47.1.0 #4、创建软连接 # 查看当前python软连接 [root@node2 Python-3.8.5]# ll /usr/bin/ |grep python -rwxr-xr-x. 1 root root 11232 Aug 13 2019 abrt-action-analyze-python lrwxrwxrwx. 1 root root 7 May 17 11:36 python -> python2 lrwxrwxrwx. 1 root root 9 May 17 11:36 python2 -> python2.7 -rwxr-xr-x. 1 root root 7216 Aug 7 2019 python2.7 #默认系统安装的是python2.7 删除python软连接 rm -rf /usr/bin/python #配置软连接为python3 ln -s /usr/local/python3/bin/python3 /usr/bin/python #这个时候看下python默认版本 python -V #删除默认pip软连接,并添加pip3新的软连接 rm -rf /usr/bin/pip ln -s /usr/local/python3/bin/pip3 /usr/bin/pip #5、更改yum配置 #因为yum要用到python2才能执行,否则会导致yum不能正常使用(不管安装 python3的那个版本,都必须要做的) vi /usr/bin/yum 把 #! /usr/bin/python 修改为 #! /usr/bin/python2 vi /usr/libexec/urlgrabber-ext-down 把 #! /usr/bin/python 修改为 #! /usr/bin/python2 vi /usr/bin/yum-config-manager #!/usr/bin/python 改为 #!/usr/bin/python2 -
代码的本地测试
#上传待处理文件 和Python脚本到Linux上 [root@node2 ~]# pwd /root [root@node2 ~]# ll -rw-r--r-- 1 root root 105 May 18 15:12 1.txt -rwxr--r-- 1 root root 340 Jul 21 16:16 mapper.py -rwxr--r-- 1 root root 647 Jul 21 16:18 reducer.py #使用shell管道符运行脚本测试 [root@node2 ~]# cat 1.txt | python mapper.py |sort|python reducer.py allen 4 apple 3 hadoop 1 hello 5 mac 1 spark 2 tom 2 -
代码提交集群执行
#上传处理的文件到hdfs #上传Python脚本到linux #提交程序执行 hadoop jar /export/server/hadoop-3.3.0/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar \ -D mapred.reduce.tasks=1 \ -mapper "python mapper.py" \ -reducer "python reducer.py" \ -file mapper.py -file reducer.py \ -input /wordcount/input/* \ -output /wordcount/outpy
知识点08:Hadoop MapReduce--输入输出路径及注意事项
-
数据都是以<key,value>键值对的形式存在的。不管是输入还是输出。
-
关于inputpath
- 指向的是一个文件,mr就处理这一个文件
- 指向的是一个目录,mr就处理该目录下所有的文件 整体当做数据集处理。
-
关于outputpath
- 要求指定的目录为空目录 不能够存储 否则执行校验失败
FileAlreadyExistsException: Output directory file:/D:/datasets/wordcount/output already exists
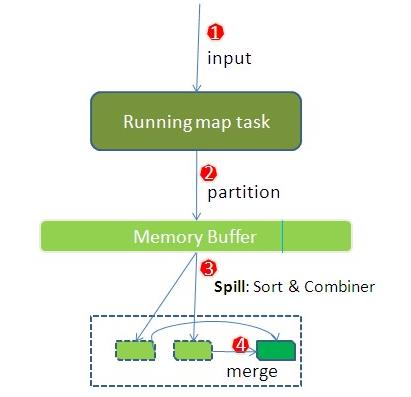
知识点09:Hadoop MapReduce--工作机制--map阶段执行流程

-
maptask并行度个数机制:逻辑切片机制。
-
影响maptask个数的因素有
文件的个数 文件的大小 split size=block size 切片的大小受数据块的大小控制
知识点10:Hadoop MapReduce--工作机制--reduce阶段执行流程
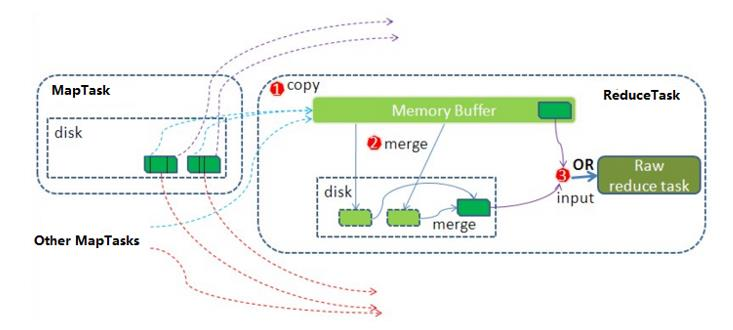
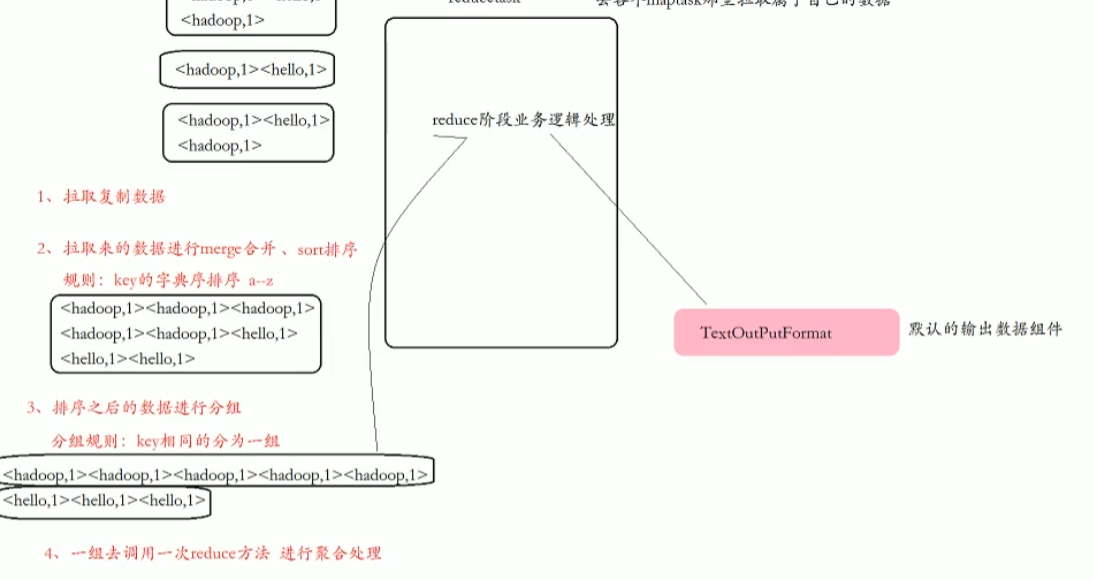
1、拉取复制数据
2、拉取来的数据进行merge合并、sort排序
规则:key的字典序排序a--z
3、排序之后的数据进行分组
分组规则:key相同的分为一组
4、一组去调用-次reduce方法进行聚合处理
业务逻辑处理
5、TextOutPutFormat默认的输出数据组件
探究:
1、reducetask个数能否改变,难道只能有--个吗?
2、rcducctask个数改变和最终输出的结果文件个数有啥关系。
默认情况下,MR程序永远只有-一个reducetask
- 影响reducetask个数的因素
-
只要用户不设置 永远默认1个
-
用户也可以通过代码进行设置 设置为几 就是几
当reducetask>=2,数据就会分区了。
-
MR的分区(partition)问题:
当MR程序中,reducetask个数>=2个的时候,对于 maptask就会涉及到一个棘手的问题:
其输出的结果应该交给哪一个reducetask来处理?
这个问题就是MR的分区问题Partition。
关键就是分区的规则:
分区的关键就是分区规则默认规则HashPartitioner哈希取模
<key,value>
key.hashcode % ReduceTask个数 == 余数 == 分区编号
默认这个规则不会保证数据平均分区, 但是会保证,只要map输出的key-样就会到同一个分区中
知识点11:Hadoop MapReduce--工作机制--shuffle机制
- Shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。
- 而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。
- shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。
- 一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
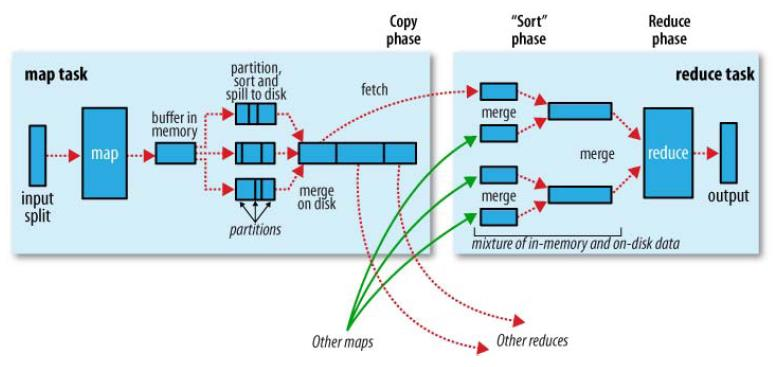
Map端Shuffle
Collect阶段:将MapTask的结果收集输出到默认大小为100M的环形缓冲区,保存之前会对key进行分区的计算,默
认Hash分区。
Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对
数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
Reducer端shuffle
Copy阶段:ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据。
Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序, ReduceTask只需保证Copy的数据的最终整体有效性即可。
shuffle的弊端
Shuffle是MapReduce程序的核心与精髓,是MapReduce的灵魂所在。
Shuffle也是MapReduce被垢病最多的地方所在。MapReduce相比较于Spark、Flink计算引l擎慢的原因,跟Shuffle机制有很大的关系。
suffle中频繁涉及到数据在内存、磁盘之间的多次往复
---------------------------------
知识点12:Hadoop YARN--功能职责概述
-
yarn是一个通用资源管理系统和调度平台。
资源指的跟程序运行相关的硬件资源 比如:CPU RAM -
资源管理系统:集群的硬件资源,和程序运行相关,比如内存、CPU等。
-
调度平台:多个程序同时申请计算资源如何分配,调度的规则(算法)。
-
通用:不仅仅支持MapReduce程序,理论上支持各种计算程序。YARN不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。
简介
- 可以把HadoopYARN理解为相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序,YARN为这些程序提供运算所需的资源(内存、CPU等)。
- Hadoop能有今天这个地位,YARN可以说是功不可没。因为有了YARN,更多计算框架可以接入到HDFS中,而不单单是MapReduce,正式因为YARN的包容,使得其他计算框架能专注于计算性能的提升。
- HDFS可能不是最优秀的大数据存储系统,但却是应用最广泛的大数据存储系统,YARN功不可没。
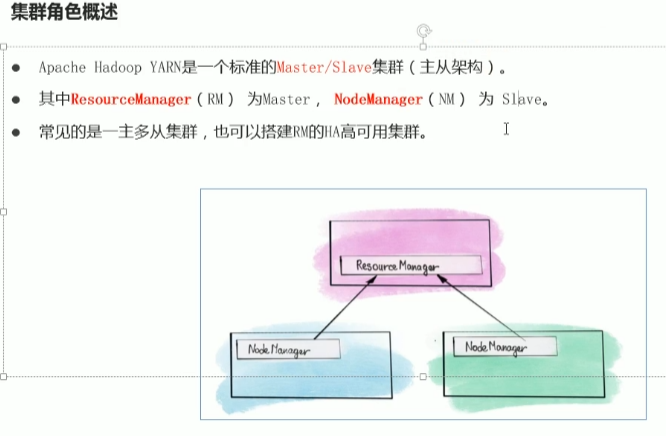
知识点13:Hadoop YARN--集群架构、yarn3大组件
官方给的图↓

-
物理层面上-2个组件
-
主角色 resourcemanager RM
ResourceManager 负责整个集群的资源管理和分配,是一个全局的资源管理系统。
是程序申请资源的唯一入口 负载调度。 -
从角色 nodemanager NM
nodemanager 负责每台机器上具体的资源管理 负责启动 关闭container容器
-
-
程序内部--1个组件
- ApplicationMaster AM
yarn作为通用资源管理系统 不关心程序的种类和程序内部的执行情况? 谁来关心程序内部执行情况? 比如MapReduce程序来说,先maptask 再运行reducetask. 需要一个组件来管理程序执行情况 程序内部的资源申请 各阶段执行情况的监督 #为了解决这个问题 yarn提供了第三个组件 applicationmaster (男)主人,雇主; 主宰; 主人; 有控制力的人; 能手; 擅长…者; #把applicationmaster称之为程序内部的老大角色 负责程序内部的执行情况 #AM针对不同类型的程序有不同的具体实现 yarn默认实现了MapReduce的AM 名字叫做MrAppMaster. 其他软件比如spark flink需要实现自己的AM 才能在yarn运行。 #结论:在上述设计模式下 任何种类程序在yarn运行,首先都是申请资源运行AM角色,然后由AM控制程序内部具体的执行。
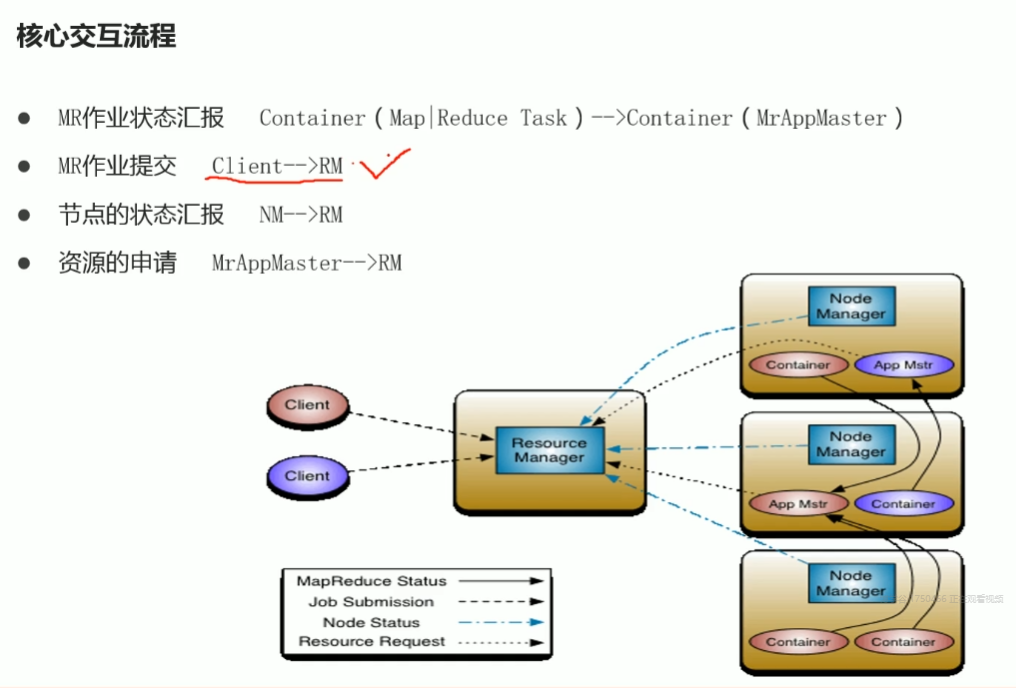
知识点14:Hadoop YARN--MR程序提交YARN流程
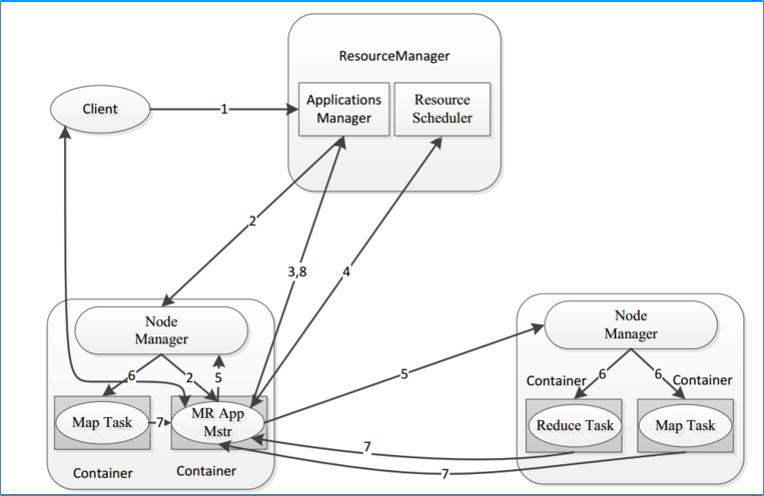
流程
- 客户端提交,客户端连接resourceManager请求资源运行本次程序的AM(Application是 Manager)
- RM指定NM预留资源,配合客户端启动容器container(图中MR App Mstr)客户端到指定的NM上,通过和NM的配合启动容器运行AM进程
- AM启动向RM进行注册,保持通信
- NM根据切片个数,向RM申请与之对应的容器运行MapTask
- Resource Scheduler:申请安排至调度队列中,根据调度策略该你执行你猜执行
- AM根据申请的容器到各个机器上和NM配合启动容器运行MapTask并监督其执行情况
- AM根据ReduceTask个数申请容器运行,过程同上
- 整个MR程序执行过程中,都是AM在申请资源、监督执行,并且把执行的情况汇报给RM(所以网页里才看得到)
- 程序运行完毕AM向RM申请回收资源,并且申请注销自己
注意:
1、YARN只负责分配资源回收资源不负责程序内部的逻辑
2、不管是客户端、还是AM,只要想申请新的资源,必须找RM,因为RM才是资源分配的唯一仲裁者
3、真正负责操心程序内部执行情况的是AM,每个程序都有自己的AM
MR ---> MrAppMaster
SparkFlink叫什么呢?后面好好学习。
知识点15:Hadoop YARN--scheduler调度策略
-
所谓的调度器指的是当集群繁忙的时候 如何给申请资源的程序分配资源
-
scheduler属于ResourceManager功能
-
YARN3大调度策略
- FIFO Scheduler 先进先出策略:绝对公平,不适合共享

- capacity Scheduler 容量调度策略:默认策略,队列内部依旧是先进先出,没大程序的时候,大程序队列就浪费了

- Fair Sheduler 公平调度策略:


- FIFO Scheduler 先进先出策略:绝对公平,不适合共享
-
Apache Hadoop版本默认策略是capacity 。CDH商业版本默认策略是Fair。
- 默认情况下,整个yarn集群在capacity策略下,划分为一个队列 名字叫做default,占整个集群资源的100.
-
决定调度策略的参数
#yarn-site.xml yarn.resourcemanager.scheduler.class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler #还可以在yarn 8088页面查看
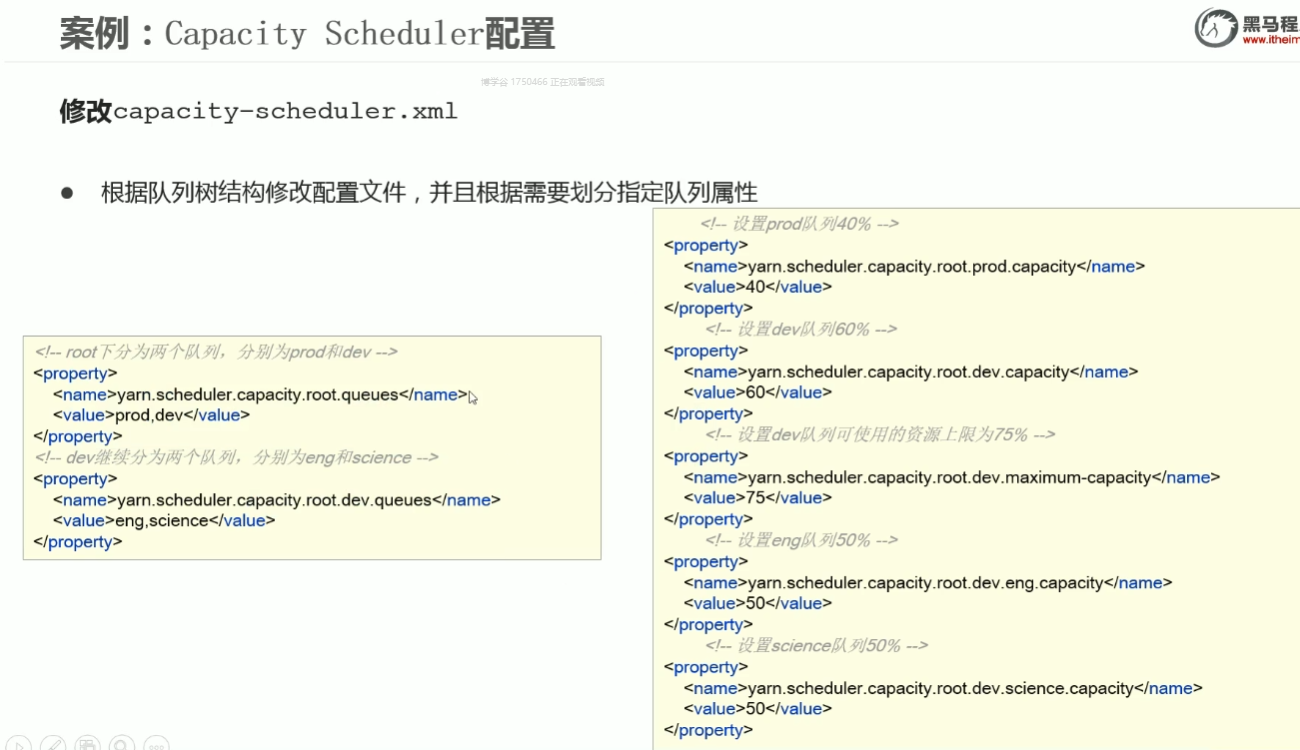
知识点16:Hadoop YARN--capacity配置示例说明
- prod 生产环境 线上环境
- dev 开发环境

---------------------------------------
知识点17:Hadoop HA集群--什么是高可用、实现高可用注意事项
背景知识:


、
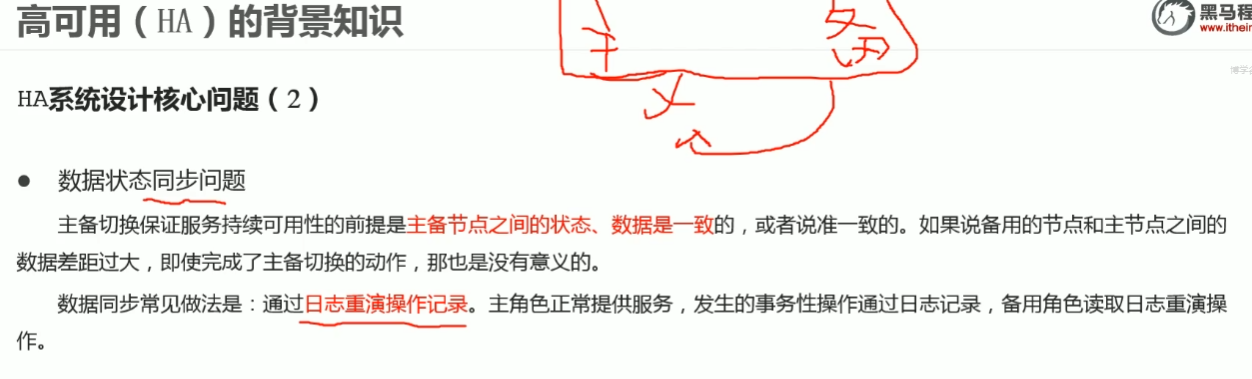

知识点18:Hadoop HA集群--HDFS HA--QJM实现原理
QJM解决单点故障
-
Hadoop中单点故障
- NameNode
- Resourcemanager
-
NameNode HA ---QJM共享日志集群方案
Quorum Journal Manager介绍
QJM全称QuorumJournal Manager(仲裁日总管理器),是Hadoop官方推荐的HDFS HA解决方案之一。
使用zookeeper中zKFC来实现主备切换;
使用JournalNode(JN)集群实现editslog的共享以达到数据同步的目的。- zkfc 实现主备切换避免脑裂
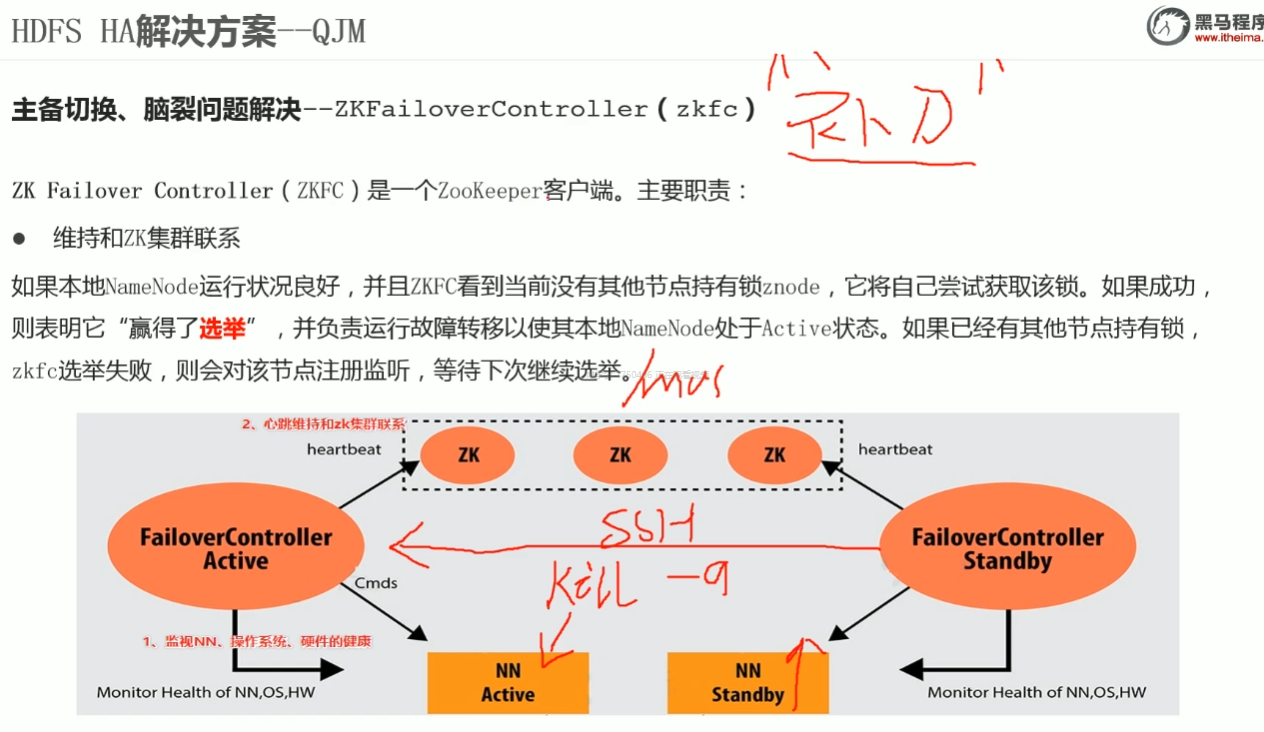

- jn(Journal Node)集群 editslog编辑日志同步
- zkfc 实现主备切换避免脑裂
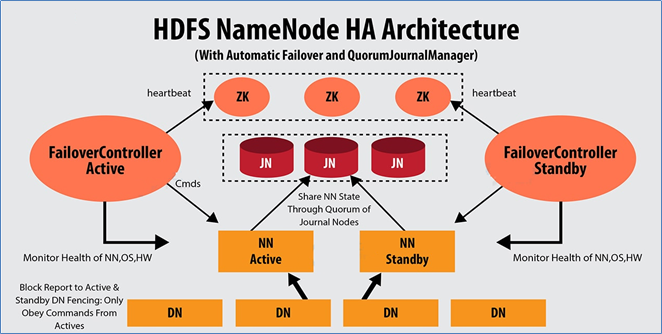
知识点19:Hadoop HA集群--YARN HA
-
Resourcemanager HA --基于zk实现
- RM需要维护的数据量很少 不像NN需要同步文件系统大量的元数据。直接基于zk即可完成
- 别忘了 zk也是一个分布式小文件存储系统。
-
Hadoop HA集群搭建 难点就是配置文件的编写



-
关于HA集群,听懂原理 可以不搭建 后续课程依然使用非HA集群。(主要考虑资源不足)
- 针对当下集群进行逻辑删除 备份
- 使用新的安装包进行编辑
今日作业
#理解分布式计算分而治之的思想
分为几步 每步做什么
如何理解map单词 如何理解reduce单词
#学会提交MapReduce程序
hadoop jar
yarn jar
#掌握MapReduce执行流程 重要
map阶段
1、maptask个数如何决定的
2、读文件组件textinputFormat 读数据行为是?
3、map处理完数据进行分区 分区是什么 默认分区规则是啥
4、缓冲区作用 0.8 100M
5、spill 溢写
6、sort排序 行为是什么
7、merge 合并
reduce阶段
0、reducetask个数如何决定的 默认1 手动设置
1、copy主动拉取自己的数据
2、merge合并
3、sort排序
4、分组 行为
5、默认输出组件textoutputFormat
shuffle机制
什么是shuffle 缺点是什么
map端shuffle有哪些步骤
reduce端shuffle有哪些步骤
#MR程序中maptask个数、reducetask个数怎么决定的
maptask影响因素(并行度个数)
reducetask影响因素(并行度个数)
人干预
#掌握YARN功能与架构组件
3个组件
RM
NM
AM
#掌握程序提交YARN交互流程 重要
申请资源就找RM
程序内部首先启动AM
#理解YARN调度策略
几个策略 默认是谁 优缺点是啥
FIFO
Capacity
Fair
#掌握Hadoop HA实现原理
HA相关名称
设计角度:如何顺利实现HA系统?
如何避免脑裂? 脑裂的后果是什么? 追求的是什么?
如何实现主备数据状态同步?
NN HA---QJM
zkfc是啥功能
jn是啥